对比学习作为一种自监督学习范式,近年来在计算机视觉和自然语言处理领域取得了突破性进展,并深刻影响了相关工程与技术研究的发展方向。其核心思想是通过构建正负样本对,学习数据表示,使相似样本在表示空间中靠近,而不相似样本则彼此远离。
一、 计算机视觉领域的演进与突破
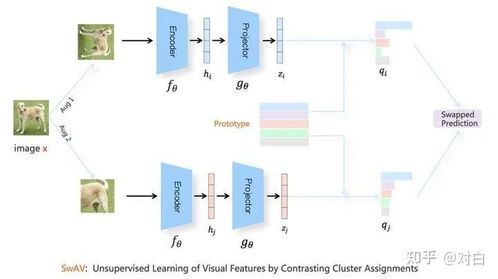
在CV领域,对比学习的兴起极大地缓解了对大规模标注数据的依赖。早期工作如InstDisc、CPC等初步验证了对比学习的可行性。里程碑式的进展出现在2020年,MoCo系列和SimCLR通过构建大规模负样本队列与更强的数据增强策略,在ImageNet分类等任务上达到了接近有监督学习的性能。随后的BYOL和SimSiam等研究进一步创新,摒弃了显式的负样本,通过非对称网络结构和停止梯度等技术实现了卓越性能,简化了训练流程。这些方法在目标检测、语义分割等下游任务的迁移性能上表现出色,推动了自监督视觉预训练模型的广泛应用。
二、 自然语言处理领域的适配与创新
在NLP领域,对比学习最初被用于改善句子表示学习,如SimCSE通过简单的“Dropout”作为数据增强方式构建正样本对,显著提升了语义文本相似度任务的性能。随着预训练语言模型的发展,对比学习被集成到BERT、GPT等模型的训练中,以获取更高质量、更均匀分布的上下文表示,缓解各向异性问题。例如,通过对比损失微调预训练模型,或在预训练阶段加入对比目标(如InfoNCE损失),增强了模型对语义相似性和细微差异的判别能力。这直接提升了文本分类、语义检索、对话系统等应用的性能。
三、 跨模态融合与统一架构
一个显著的趋势是CV与NLP在对比学习框架下的融合。CLIP模型是典范之作,它通过海量的图像-文本对进行对比学习,实现了开放世界的视觉概念理解,其“提示词工程”范式革新了零样本图像分类。ALIGN、Florence等后续工作进一步扩展了规模和能力。这种跨模态对比学习催生了多模态大模型的研究热潮,为图像生成、跨模态检索等任务提供了强大基础。
四、 工程与技术研究发展
在工程化与试验发展层面,对比学习的研究重点正朝着效率、可扩展性和理论理解深化:
- 效率优化:研究如何减少对大批量和海量负样本的依赖,如通过内存库、动量编码器,或探索更高效的正样本构建策略。
- 理论探索:深入分析对比学习成功的内在机理,如均匀性-容忍性的权衡、特征坍缩的避免机制,以及它与互信息最大化的理论联系。
- 规模化与部署:研究如何将对比学习框架高效地部署到超大规模数据集和模型上,并探索其在联邦学习、边缘计算等场景下的应用。
- 领域特定适配:在医疗影像、遥感、工业质检等特定领域,结合领域知识设计专用的数据增强和正负样本对构建策略,以解决标注数据稀缺问题。
结论
对比学习已成为CV和NLP领域构建基础模型的支柱技术之一。它不仅推动了学术前沿的突破,更通过提供强大的预训练表示,降低了诸多下游AI任务对标注数据的门槛,加速了人工智能技术的产业化落地。随着对学习动力学更深刻的理论理解,以及与大语言模型、扩散模型等技术的进一步结合,对比学习有望在实现更通用、更高效的人工智能系统中持续发挥关键作用。